hive详解
”hive 详细“ 的搜索结果
Hive简介Hive:由FaceBook开源用于解决海量结构化日志的数据统计工具Hive:基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL的查询功能。Hive本质将HSQL转化成MapReduce程序Hive处理...
第1章 Hive入门 1.1 什么是Hive 1.2 Hive的优缺点 1.2.1 优点 1.2.2 缺点 1.3 Hive架构原理 1.4 Hive和数据库比较 1.4.1 查询语言 1.4.2 数据存储位置 1.4.3 数据更新 1.4.4 索引 1.4.5 执行 1.4.6 执行...
Hive 一、Hive基本概念 1.1、Hive简介 什么是Hive Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL)。 其本质是将SQL转换为MapReduce的...
Hive详细介绍及简单应用
标签: hive
1.Hive基本概念 1.1Hive简介 1.1.1什么是Hive Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 1.1.2为什么使用Hive 1.)直接使用hadoop所面临的问题 ...

Apache Flink 从 1.9.0 版本开始增加了与 Hive 集成的功能,用户可以通过 Flink 来访问 Hive 的元数据,以及读写 Hive 中的表,Hive 是大数据领域最早出现的 SQL 引擎,发展至今有着丰富的功能和广泛的用户基础。...
为什么选择Hive?基于Hadoop的大数据的计算/扩展能力支持SQL like查询语言统一的元数据管理简单编程Hive的安装1.1在hadoop生态圈中属于数据仓库的角色。他能够管理hadoop中的数据,同时可以查询hadoop中的数据。本质...



Hive调优及参数优化,涵盖:基础配置优化、压缩配置优化、分桶优化、Map Join、Bucket-Map Join、SMB Join、Hive并行操作、Hive索引、数据清洗转换优化、统计分析优化、Hive优化器等等......
1.SparkSQL 整合 Hive 导读 开启Hive的MetaStore独立进程 整合SparkSQL和Hive的MetaStore 和一个文件格式不同,Hive是一个外部的数据存储和查询引擎, 所以如果Spark要访问Hive的话, 就需要先整合Hive ...
hive是facebook开源,并捐献给了apache组织,作为apache组织的顶级项目(hive.apache.org)。 hive是一个基于大数据技术的数据仓库(DataWareHouse)技术,主要是通过将用户书写的SQL语句翻译成MapReduce代码,然后发布...
Hive常用函数大全



Hive是Hadoop组态中的数据仓库,本质是将sql语句转换为MapReduce任务,所以Hive只是一个解析引擎,它的数据存储在hdfs上,元数据信息依托mysql数据库。在这里有一个小问题,为什么需要mysql关系数据库,因为hdfs存储...

学习hive之路就此开启啦,让我们共同努力。
Hive:启动Hive

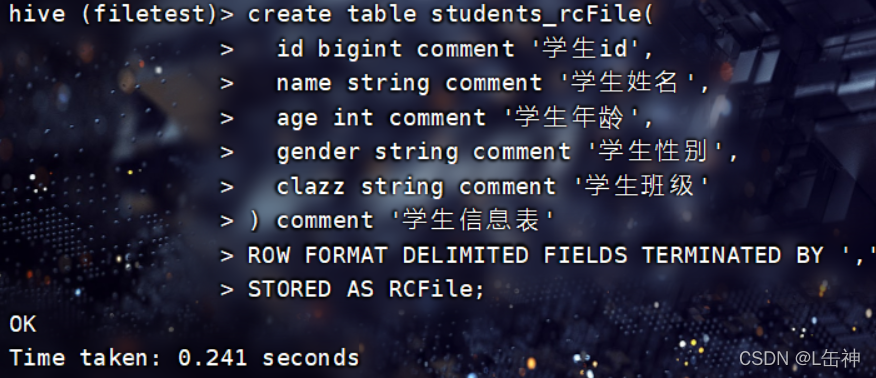
Hive介绍 Hive是一个在Hadoop中用来处理结构化数据的数据仓库基础工具,用来进行数据提取、转化、加载,可以存储、查询和分析存储在Hadoop中的大规模数据。它架构在Hadoop之上,总归为大数据工具,并使得查询和...
Hive 自定义函数
标签: 后端
数据仓库工具hive是基于Hadoop集群运行的,在安装hive之前,确保电脑已经启动Hadoop集群。 1.安装单用户模式 对hive软件包进行上传解压,重命名后,输入命令启动hive。 [root@master ~]# cd /export/software/ ...

推荐文章
- GBDT和随机森林-附原版动画PPT(技术分享也可以文艺范?)_随机森林讲解ppt下载-程序员宅基地
- pip3升级报错:PermissionError: [Errno 13] Permission denied: '/usr/bin/pip' -> '/tmp/pip-yndfk0h8-uninsta_oserror: [errno 13] permission denied: '/usr/bin/p-程序员宅基地
- TortoiseGit github 免输用户名密码 Push_github tortoise 密码-程序员宅基地
- Docker 下查看Redis版本的命令_docker redis版本查询-程序员宅基地
- keep-alive在路由中的使用_arco pro 路由keep alive-程序员宅基地
- quill-better-table:赋予quill富文本编辑器强大的表格编辑功能!-程序员宅基地
- Struts1的路径映射详解_struts1 path-程序员宅基地
- QoS---拥塞管理、拥塞避免_qos流队列模板-程序员宅基地
- 数据库设计--实体关系图(ERD)_er图中,实体,属性,联系分别用-程序员宅基地
- Matlab 中卷积运算傅里叶变换的一些验证_matlab傅里叶变换代替图像的卷积计算-程序员宅基地